機械学習モデルのトレーニング
機械学習モデルを、これに含まれているラベル付け情報に基づいてトレーニングします。
機械学習モデルを正常にトレーニングするには、選択した分類子内で2つ以上のラベルを定義する必要があります。モデルをトレーニングするには、すべてのラベルを3つ以上のパートに割り当てる必要があります。
ヒント: 上記の条件の一方または両方が満たされていないために、トレーニングを正常に行えない場合は、ステータスバーに表示されるメッセージに従って、欠落しているラベル情報を提供し、モデルのトレーニングを進めてください。
-
Assemblyリボンから、ツールをクリックします。

図 1. -
Trainをクリックします。
機械学習モデルをトレーニングした後に、すべてのトレーニング情報を含むバイナリファイル(<classifier_name>_<train_iteration>.aic)がClassifierフォルダーに保存されます。分類子に新しいラベルを追加した場合や、現在のラベル割り当て内容を変更した場合は、機械学習モデルを再トレーニングしてそれらの変更を適用します。注: トレーニング操作が成功するたびに、<train_iteration>の値が1だけ増分されます。トレーニングの繰り返し数は0から始まり、train_iteration > 0の場合にのみ、<train_iteration>サフィックスがファイル名に付加されます。
モデルトレーニングの結果として生成されるバイナリ(.aic)ファイルは、複数のマシンで使用できます。したがって、上級ユーザーは分類子を作成して、機械学習モデルをトレーニングすることで、他のユーザーがパート分類を実行するためのファイルを提供でき、分類子をトレーニングする必要がなくなります(学習済みモデルファイルの追加を参照)。
ヒント: 必要に応じて、ガイドバーから をクリックし、Generate Log
Fileを選択します。ログファイル(<classifier_name>_<train_iteration>_log.txt)は、機械学習モデルのトレーニング後に、Classifierフォルダーに保存されます。
をクリックし、Generate Log
Fileを選択します。ログファイル(<classifier_name>_<train_iteration>_log.txt)は、機械学習モデルのトレーニング後に、Classifierフォルダーに保存されます。
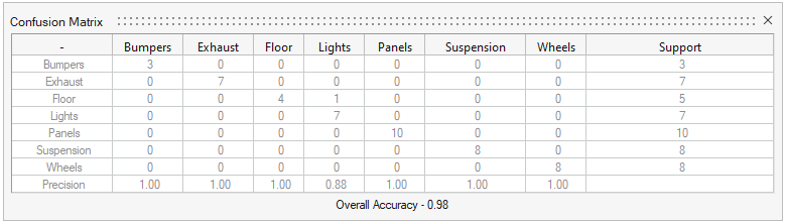
図 2. 混同行列
各行には、ラベル名と、ユーザーによってそのラベルが割り当てられたパートの合計数が表示されます。この総和はSupport列に表示されます。
各列には、機械学習モデルによって予測されたラベルが表示されます。
- Precision
- 特定タイプの正しく予測されたラベルの数の、それと同じラベルの予測総数に対する比率。この比率から、機械学習モデルがラベルをどれだけ正しく予測できるのかが分かります。
- Support
- 各ラベル(ユーザー定義)が割り当てられたパートの合計数。
- Overall Accuracy
- 予測総数に対する正しい予測数の全体での比率。
図 2に例を示しています。
Floor行では、Floor列に“4”、Lights列に“1”と表示されています。これは、Support列の総数でわかるように、ユーザーによって5つのFloorラベルがパートに割り当てられたことを意味します。
Floor列の“4”は、Floorラベルには4個のパートがあると機械学習モデルが予測したことを意味します。パートがFloorであると機械学習モデルが予測した場合は常に正しい予測だったため、この精度は1になります。
Lights行については、Support列の“7”という数字は、7個のLightsラベルがパートに割り当てられたことを意味します。しかし、Lights列では、Floor行に“1”、Lights行に“7”と表示されています。これは、機械学習モデルは8個のパートがライトであると予測し、そのうち7回の予測は正しかったものの、1回については、Floorラベルが割り当てられたパートがライトであると間違って予測されたということです。したがって、Lightsの予測精度は7/8=0.88です。
全体の精度の値は、混同行列のSupport列の列合計に対する対角成分の合計の比率として計算されます。したがって、次のようになります:(1)
注: トレーニング結果は、パートにラベルが割り当てられる順序に影響を受けることがあります。各ラベルに割り当てられるパートの数が増えると、この影響は大幅に低減されます。